Uji Hipotesis
Ketika ada dua data yang ingin dibandingkan, pertanyaan yang biasanya diajukan adalah: “Apakah kedua data tersebut berbeda?” Jawabannya diberikan oleh uji hipotesis: dengan uji-t jika data terdistribusi normal, atau dengan uji Mann-Whitney untuk data yang tidak terdistribusi normal. Jadi apa yang terjadi jika ada lebih dari dua kelompok?
Untuk menjawab pertanyaan "Apakah data-data tersebut berbeda?" untuk data yang lebih dari dua kelompok, Analysis of Variance (ANOVA) digunakan untuk data yang residualnya berdistribusi normal. Jika kondisi ini tidak terpenuhi maka harus dilakukan Uji Kruskal-Wallis.
Apa yang harus dilakukan jika ada data berpasangan?
Jika ada pasangan yang cocok untuk dua kelompok, dan perbedaannya tidak terdistribusi normal, dapat digunakan tes jumlah peringkat bertanda Wilcoxon. Uji peringkat untuk lebih dari dua kelompok data yang cocok adalah uji Friedman.
Disarankan: Jika pengukuran berulang satu arah ANOVA tidak sesuai, transformasi peringkat yang diikuti oleh ANOVA akan memberikan uji yang lebih kuat dengan kekuatan statistik yang lebih besar daripada uji Friedman.
Uji-t, biasanya dilakukan untuk menemukan bukti perbedaan yang signifikan antara rata-rata populasi (2-sampel t) atau antara rata-rata populasi dan nilai yang dihipotesiskan (1-sampel t). Nilai-t mengukur ukuran perbedaan relatif terhadap variasi data sampel. Dengan kata lain, T hanyalah selisih yang dihitung yang direpresentasikan dalam satuan kesalahan standar. Semakin besar nilai T, semakin besar bukti yang melawan hipotesis nol. Artinya terdapat bukti yang lebih besar bahwa terdapat perbedaan yang signifikan. Semakin dekat T ke 0, semakin besar kemungkinan tidak ada perbedaan yang signifikan.
Nilai-t dalam output dihitung hanya dari satu sampel dari seluruh populasi. Jika diambil sampel data acak berulang dari populasi yang sama, akan didapatkan nilai-t yang sedikit berbeda setiap kali, karena kesalahan pengambilan sampel acak (yang sebenarnya bukan kesalahan apa pun – berupa variasi acak dalam data).
Dalam setiap percobaan, terdapat pengaruh atau perbedaan antar kelompok yang diuji oleh peneliti. Bisa jadi keefektifan obat baru, bahan bangunan, atau intervensi lain yang memiliki manfaat. Sayangnya bagi para peneliti, selalu ada kemungkinan tidak ada pengaruh, yaitu tidak ada perbedaan antar kelompok. Tidak adanya perbedaan yang signifikan ini disebut sebagai hipotesis nol.
Meskipun hipotesis nol benar, sangat mungkin bahwa akan ada efek dalam data sampel karena kesalahan pengambilan sampel acak. Faktanya, sangat tidak mungkin bahwa kelompok sampel akan pernah sama persis dengan nilai hipotesis nol. Akibatnya, posisinya adalah bahwa perbedaan yang diamati dalam sampel tidak mencerminkan perbedaan yang sebenarnya antar populasi.
Nilai P mengevaluasi seberapa baik data sampel mendukung argumen bahwa hipotesis nol benar. Ini mengukur seberapa kompatibel data dengan hipotesis nol. Seberapa besar kemungkinan efek yang diamati dalam data sampel jika hipotesis nol benar?
- Nilai P tinggi: kemungkinan besar data mengikuti hipotesis nol.
- Nilai P rendah: data tidak mungkin mengikuti hipotesis nol.
Nilai P yang rendah menunjukkan bahwa sampel memberikan cukup bukti bahwa hipotesis nol dapat ditolak untuk seluruh populasi.
Dalam istilah teknis, nilai P adalah probabilitas untuk memperoleh efek setidaknya sama ekstrimnya dengan yang ada dalam data sampel, dengan asumsi kebenaran hipotesis nol.
Misalnya, studi vaksin menghasilkan nilai P 0,04. Nilai P ini menunjukkan bahwa jika vaksin tidak berpengaruh, akan diperoleh perbedaan yang diamati lebih dari 4% penelitian karena kesalahan pengambilan sampel secara acak.
Nilai P hanya menjawab satu pertanyaan: seberapa besar kemungkinan, dengan asumsi hipotesis nol yang benar?
Uji t di bawah ini mencoba menghitung nilai T dan p untuk data 'mean radius' dan 'mean area' dari dataset 'breast cancer'. Nilai p yang diperoleh di bawah 0.05 sehingga dikatakan 'tidak ada perbedaan signifikan' antara kedua data, dengan asumsi varians kedua data





Ketika digunakan analisis dengan variansi yang tidak sebanding, diperoleh nilai p sebagai berikut:
Uji-t berpasangan
Ketika membandingkan dua kelompok satu sama lain, harus dibedakan antara dua kasus.
Dalam kasus pertama, membandingkan dua nilai yang direkam dari subjek yang sama pada dua waktu tertentu. Misalnya, pengukuran jumlah siswa saat mereka masuk sekolah dasar dan setelah tahun pertama mereka, dan periksa apakah mereka telah bertambah. Karena kita hanya tertarik pada perbedaan antara pengukuran pertama dan kedua, tes ini disebut uji-t berpasangan, dan pada dasarnya setara dengan uji-t satu sampel untuk perbedaan rata-rata.
Uji-t sampel berpasangan juga disebut uji-t sampel dependen. Ini adalah tes univariat yang menguji perbedaan yang signifikan antara 2 variabel terkait. Contohnya adalah jika Anda di mana mengumpulkan tekanan darah untuk seseorang sebelum dan sesudah beberapa perawatan, kondisi, atau titik waktu.
Hipotesis yang diuji adalah:
- Hipotesis nol (H0): ud = 0, yang berarti selisih rata-rata antara sampel 1 dan sampel 2 sama dengan 0.
- Hipotesis alternatif (HA): ud ≠ 0, yang berarti perbedaan rata-rata antara sampel 1 dan sampel 2 tidak sama dengan 0.
Jika nilai p kurang dari yang diuji, paling sering 0,05, hipotesis nol dapat ditolak.
Asumsi Uji t Sampel
Agar hasil uji-t sampel berpasangan dapat dipercaya, asumsi berikut harus dipenuhi:
- Variabel terikat (DV) harus kontinu yang diukur pada skala interval atau rasio
- Pengamatannya independen
- DV harus didistribusikan secara normal
- Uji-t sampel berpasangan kuat untuk pelanggaran ini. Jika terdapat pelanggaran normalitas, selama tidak dalam pelanggaran berat maka hasil tes dianggap valid
- DV tidak boleh mengandung pencilan yang signifikan
Jika salah satu asumsi ini dilanggar, pengujian yang berbeda harus digunakan. Sebuah alternatif untuk uji-t sampel berpasangan adalah Uji peringkat bertanda Wilcoxon.
Data yang digunakan dalam contoh ini
Data yang digunakan dalam contoh merupakan kumpulan data fabrikasi dan berisi pembacaan tekanan darah sebelum dan sesudah intervensi. Ini adalah variabel "bp_before" dan "bp_after".
CONTOH T-TEST SAMPEL BERPASANGAN
Hal pertama yang perlu kita lakukan adalah mengimpor pustaka statistik dan kemudian menguji asumsi uji-t sampel berpasangan. Pertama, mari kita periksa pencilan yang signifikan di masing-masing variabel.

Tampaknya tidak ada pencilan yang signifikan dalam variabel. Sekarang untuk menguji bahwa data tersebut berasal dari distribusi normal. Ada dua cara untuk menguji asumsi ini - membuat histogram, dan / atau menggunakan uji statistik. Ayo lakukan keduanya.

Histogram data kami tampaknya tidak terdistribusi normal. Tampaknya ada kemiringan. Mari kita uji statistik ini untuk melihat apakah data terdistribusi normal. Untuk menguji ini, seseorang dapat menggunakan uji Shapiro-Wilk untuk normalitas. Sayangnya keluarannya tidak diberi label. Nilai pertama adalah nilai uji W, dan nilai kedua adalah nilai p.
Kedua variabel tersebut melanggar asumsi normalitas dengan jumlah yang besar. Oleh karena itu, seseorang harus menggunakan tes yang berbeda untuk menganalisis data ini. Seperti yang disebutkan di awal, alternatif yang tepat untuk digunakan adalah Uji peringkat bertanda Wilcoxon. Namun, untuk tujuan demonstrasi, saya akan terus menggunakan uji-t sampel berpasangan. Perlu dicatat, bahwa temuan dari analisis ini tidak boleh dianggap valid karena banyaknya pelanggaran asumsi tentang normalitas.
Untuk melakukan uji-t sampel berpasangan, seseorang perlu menggunakan metode stats.ttest_rel ().
Hasil uji t berpasangan signifikan secara statistik! Sehingga hipotesis nol dapat ditolak.
Komponen lain yang diperlukan untuk melaporkan hasil uji adalah derajat kebebasan (df). df dapat dihitung dengan mengambil jumlah total observasi berpasangan dikurangi 1. Dalam kasus ini, df = 120 - 1 = 119.
INTERPRETASI HASIL
Uji-t sampel berpasangan digunakan untuk menganalisis tekanan darah sebelum dan sesudah intervensi untuk menguji apakah intervensi memiliki pengaruh yang signifikan pada tekanan darah. Tekanan darah sebelum intervensi lebih tinggi (156,45 ± 11,39 unit) dibandingkan tekanan darah pasca intervensi (151,36 ± 14,18 unit); ada penurunan tekanan darah yang signifikan secara statistik (t (119) = 3,34, p = 0,0011) sebesar 5,09 unit.
Catatan: Asumsi normalitas dilanggar, hasil tidak boleh dipercaya. Data harus dianalisis menggunakan Uji peringkat bertanda Wilcoxon.
Uji-t Tidak Berpasangan
Tes kedua untuk membandingkan dua kelompok independen. Misalnya, membandingkan efek dari dua obat yang diberikan kepada dua kelompok pasien yang berbeda, dan membandingkan bagaimana kedua kelompok tersebut merespons. Ini disebut uji-t tidak berpasangan, atau uji-t untuk dua kelompok independen.
Jika ada dua sampel independen, varians dari selisih antara rata-rata mereka adalah jumlah dari varian yang terpisah, jadi kesalahan standar dari perbedaan rata-rata adalah akar kuadrat dari jumlah varian terpisah:
di mana x¯i adalah mean dari sampel ke-i, dan se menunjukkan kesalahan standar.
Dengan munculnya daya komputasi yang murah, pemodelan statistik telah menjadi bidang yang berkembang pesat. Hal ini juga memengaruhi analisis statistik klasik, karena sebagian besar masalah dapat dilihat dari dua perspektif: membuat hipotesis statistik, dan memverifikasi atau memalsukan hipotesis itu; atau membuat model statistik, dan menganalisis signifikansi parameter model.
Pengukuran performa dari tim balap, pada dua kesempatan berbeda. Selama Race_1, anggota tim mencapai skor [79., 100., 93., 75., 84., 107., 66., 86., 103., 81., 83., 89., 105 ., 84., 86., 86., 112., 112., 100., 94.], dan selama Race_2 [92., 100., 76., 97., 72., 79., 94., 71 ., 84., 76., 82., 57., 67., 78., 94., 83., 85., 92., 76., 88.].
Angka-angka ini dapat dibuat, dan uji-t yang membandingkan kedua grup dapat dilakukan, sebagai berikut:
Perintah random.seed (123) menginisialisasi pembuat angka acak dengan angka 123, yang memastikan bahwa dua kode yang berjalan secara berurutan menghasilkan hasil yang sama, sesuai dengan angka yang diberikan di atas.
Garis penting adalah yang terakhir tetapi satu, yang membuahkan hasil. Dengan demikian fungsi ordinary least square (ols) dari statsmodels menguji model yang menggambarkan perbedaan antara hasil Race1 dan Race2 hanya dengan offset (juga disebut intersep dalam bahasa pemodelan). Dengan kata lain, model kita hanya memiliki satu parameter, yaitu intersep. Hasil di bawah ini menunjukkan bahwa probabilitas intersep ini adalah 0 hanya 0,03: perbedaannya signifikan.
Perbandingan Non-parametrik Dua Grup: Uji Mann-Whitney
Jika nilai pengukuran dari kedua kelompok tidak terdistribusi normal, kita harus menggunakan uji non-parametrik. Tes yang paling umum untuk itu adalah tes Mann-Whitney (-Wilcoxon). Hati-hati, karena tes ini terkadang juga disebut sebagai tes peringkat-sum Wilcoxon. Ini berbeda dari tes jumlah peringkat yang ditandai Wilcoxon!
Jika data tidak berdistribusi normal, uji-t tidak dapat digunakan (meskipun uji ini cukup kuat terhadap penyimpangan dari normalitas). Sebaliknya, uji non-parametrik pada nilai rata-rata digunakan. Tes jumlah peringkat bertanda tangan Wilcoxon dapat diterapkan.
Metode ini memiliki tiga langkah:
- Hitung perbedaan antara setiap observasi dan nilai target yang diminati.
- Abaikan tanda-tanda perbedaan, rangking menurut besarnya.
- Hitung jumlah peringkat semua peringkat negatif (atau positif), sesuai dengan pengamatan di bawah (atau di atas) nilai hipotesis yang dipilih.
Dalam Tabel di bawah ini adalah contoh, di mana signifikansi terhadap penyimpangan dari nilai 7725 diuji. Jumlah peringkat dari nilai negatif memberikan 3 + 5 = 8, dan dapat dicari di tabel terkait untuk menjadi signifikan. Dalam praktiknya, program komputer Anda saat ini akan melakukan ini. Contoh ini juga menunjukkan fitur lain dari evaluasi peringkat: nilai terikat (di sini 7515) diberikan peringkat rata-rata (di sini 1.5).
Perbedaan tinggi tanaman jagung hasil persilangan dan tanaman jagung hasil pemupukan sendiri adalah sebagai berikut:
Tanaman yang dibuahi silang tampak lebih tinggi. Untuk menguji hipotesis nol bahwa tidak ada perbedaan ketinggian, kita dapat menerapkan uji dua sisi:
Oleh karena itu, kami akan menolak hipotesis nol pada tingkat kepercayaan 5%, menyimpulkan bahwa ada perbedaan ketinggian antara kelompok. Untuk memastikan bahwa median dari perbedaan dapat diasumsikan positif, kami menggunakan:
Hal ini menunjukkan bahwa hipotesis nol bahwa median negatif dapat ditolak pada tingkat kepercayaan 5% dengan alternatif bahwa median lebih besar dari nol. Nilai p di atas tepat. Menggunakan pendekatan normal memberikan nilai yang sangat mirip:
Perhatikan bahwa statistik berubah menjadi 96 dalam kasus satu sisi (jumlah peringkat perbedaan positif) sedangkan itu adalah 24 dalam kasus dua sisi (jumlah minimum peringkat di atas dan di bawah nol).
Analisis Varians
Ide di balik ANalysis Of VAriance (ANOVA) adalah untuk membagi varians menjadi varians antara kelompok, dan dalam kelompok, dan melihat apakah distribusi tersebut cocok dengan hipotesis nol bahwa semua kelompok berasal dari distribusi yang sama. Variabel yang membedakan kelompok yang berbeda sering disebut faktor.
(Sebagai perbandingan, uji-t melihat nilai rata-rata dua kelompok, dan memeriksa apakah itu konsisten dengan asumsi bahwa kedua kelompok berasal dari distribusi yang sama.)
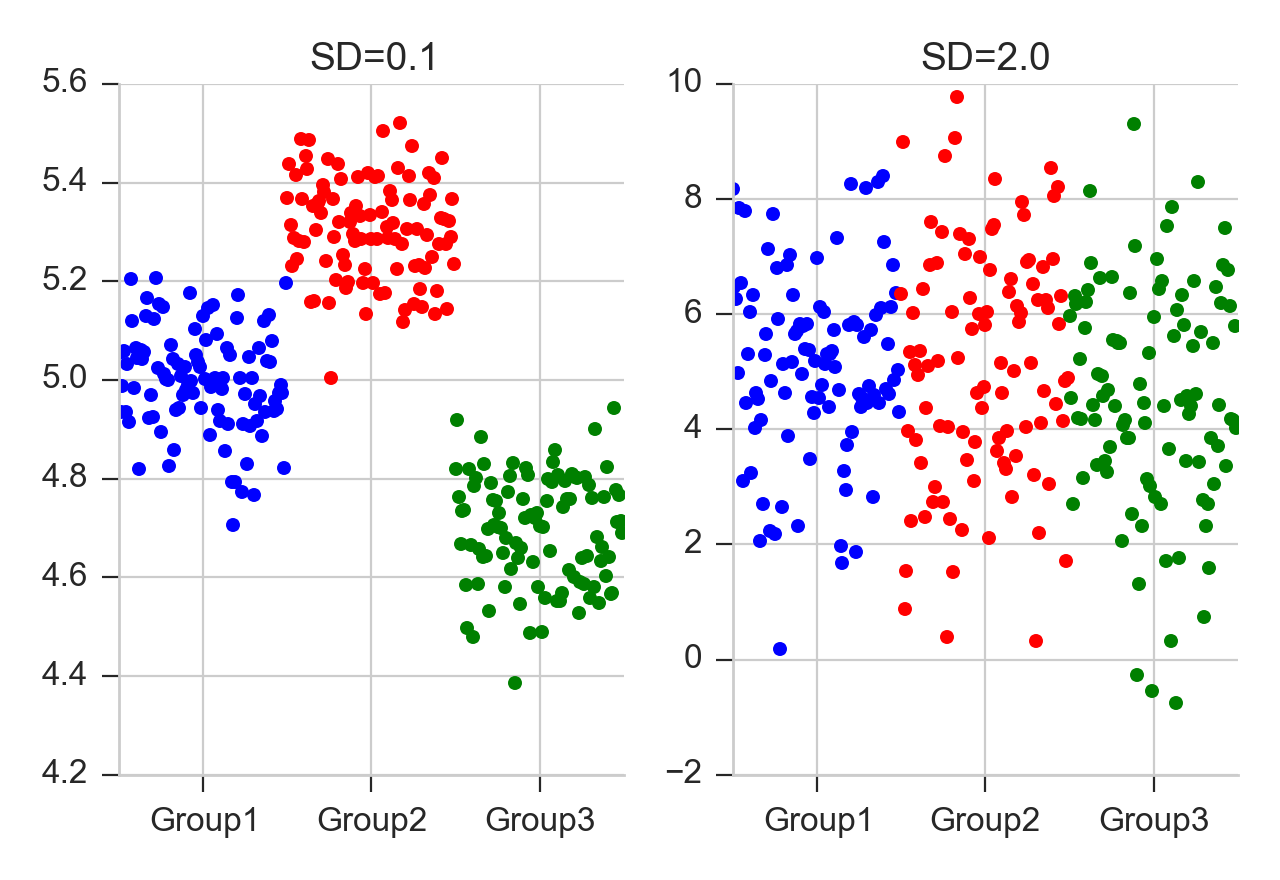
Dalam kedua kasus tersebut, perbedaan antara kedua kelompok adalah sama. Tetapi kiri, perbedaan dalam kelompok lebih kecil daripada perbedaan antar kelompok, sedangkan kanan, perbedaan dalam kelompok lebih besar daripada perbedaan antar kelompok.
Misalnya, jika kita membandingkan kelompok dengan Tidak ada perlakuan, kelompok lain dengan perlakuan A, dan kelompok ketiga dengan perlakuan B, maka kita melakukan ANOVA satu faktor, kadang-kadang juga disebut ANOVA satu arah, dengan "pengobatan" faktor analisis satu. Jika kami melakukan tes yang sama dengan pria dan wanita, maka kami memiliki ANOVA dua faktor atau dua arah, dengan “jenis kelamin” dan “perlakuan” sebagai dua faktor pengobatan. Perhatikan bahwa dengan ANOVA, sangat penting untuk memiliki jumlah sampel yang persis sama di setiap kelompok analisis!
Karena hipotesis nol adalah bahwa tidak ada perbedaan antara kelompok, tes ini didasarkan pada perbandingan variasi yang diamati antara kelompok (yaitu antara rata-rata mereka) dengan yang diharapkan dari variabilitas yang diamati antara subjek. Perbandingan mengambil bentuk umum uji F untuk membandingkan varians, tetapi untuk dua kelompok, uji t menghasilkan jawaban yang persis sama.

Garis biru panjang menunjukkan mean utama atas semua data. SS {Error} menjelaskan variabilitas “di dalam” grup, dan SS {Treatment} (dijumlahkan di semua poin masing-masing!) Variabilitas“ di antara ”grup.
ANOVA satu arah mengasumsikan semua sampel diambil dari populasi yang terdistribusi normal dengan varian yang sama. Untuk menguji asumsi tersebut, dapat digunakan uji Levene.
ANOVA menggunakan terminologi standar tradisional. Persamaan definisi varians sampel adalah s2 = 1n − 1∑ (yi − y¯) 2, di mana pembagi disebut derajat kebebasan (DF), penjumlahannya disebut penjumlahan kuadrat (SS), hasilnya disebut mean square (MS) dan suku kuadrat adalah deviasi dari mean sampel. ANOVA memperkirakan 3 varian sampel: varian total berdasarkan semua penyimpangan pengamatan dari rata-rata utama, varian kesalahan berdasarkan semua penyimpangan pengamatan dari sarana perlakuan yang sesuai, dan varian perlakuan. Varians perlakuan didasarkan pada deviasi sarana perlakuan dari mean utama, hasilnya dikalikan dengan jumlah observasi pada setiap perlakuan untuk memperhitungkan perbedaan antara varians observasi dan varians mean. Jika hipotesis nol benar, ketiga perkiraan varians adalah sama (dalam kesalahan pengambilan sampel).
Teknik fundamental adalah pembagian jumlah total kotak SS menjadi komponen yang terkait dengan efek yang digunakan dalam model. Misalnya, model untuk ANOVA yang disederhanakan dengan satu jenis perlakuan di berbagai tingkatan.
Jumlah derajat kebebasan DF dapat dipartisi dengan cara yang sama: salah satu komponen ini (untuk kesalahan) menentukan distribusi chi-kuadrat yang menggambarkan jumlah kuadrat terkait, sedangkan hal yang sama berlaku untuk "perlakuan" jika ada tidak ada efek pengobatan.
Contoh: ANOVA satu arah Sebagai contoh, mari kita ambil kadar folat sel darah merah (μg / l) dalam tiga kelompok pasien bypass jantung yang diberi tingkat ventilasi nitrous oksida yang berbeda (Amess et al, 1978), dijelaskan dalam contoh kode Python di bawah ini. Saya pertama kali menunjukkan hasil tes ANOVA ini, dan kemudian menjelaskan langkah-langkah menuju ke sana.
- Pertama, Jumlah kuadrat (SS) dihitung. Di sini SS antar perlakuan adalah 15515.88, dan SS residu adalah 39716.09. SS total adalah jumlah dari dua nilai ini.
- The mean square ("MS") adalah SS dibagi dengan derajat kebebasan yang sesuai ("df").
- Uji F atau uji rasio varian digunakan untuk membandingkan faktor-faktor penyimpangan total. Nilai F adalah nilai rata-rata kuadrat yang lebih besar dibagi dengan nilai yang lebih kecil. (Jika kita hanya memiliki dua kelompok, nilai F adalah kuadrat dari nilai t yang sesuai. Lihat daftar di bawah.)
- Di bawah hipotesis nol bahwa dua populasi yang terdistribusi normal memiliki varian yang sama, kami mengharapkan rasio dari dua varian sampel memiliki Distribusi F. Dari nilai F, kita dapat mencari nilai p yang sesuai.
Tes ANOVA memiliki asumsi penting yang harus dipenuhi agar nilai p yang terkait menjadi valid.
- Sampelnya independen.
- Setiap sampel berasal dari populasi yang berdistribusi normal.
- Deviasi standar populasi dari semua kelompok sama. Sifat ini dikenal sebagai homoskedastisitas.
Jika asumsi ini tidak benar untuk kumpulan data tertentu, masih mungkin untuk menggunakan uji-H Kruskal-Wallis meskipun dengan beberapa kehilangan daya.
Panjang setiap grup setidaknya harus satu, dan harus ada setidaknya satu grup dengan panjang lebih dari satu. Jika kondisi ini tidak terpenuhi, peringatan akan dibuat dan (np.nan, np.nan) dikembalikan.
Jika setiap grup berisi nilai konstan, dan setidaknya terdapat dua grup dengan nilai berbeda, fungsi tersebut menghasilkan peringatan dan mengembalikan (np.inf, 0).
Jika semua nilai di semua grup sama, fungsi menghasilkan peringatan dan mengembalikan (np.nan, np.nan).
Berikut beberapa data pengukuran cangkang kerang Mytilus trossulus dari lima lokasi: Tillamook, Oregon; Newport, Oregon; Petersburg, Alaska; Magadan, Rusia; dan Tvarminne, Finlandia, diambil dari kumpulan data yang jauh lebih besar yang digunakan di McDonald et al. (1991).
f_oneway menerima input berjajar multidimensi. Ketika input multidimensi dan sumbu tidak diberikan, pengujian dilakukan sepanjang sumbu pertama dari input berjajar. Untuk data berikut, pengujian dilakukan tiga kali, satu kali untuk setiap kolom.
Perbandingan Lebih dari Dua
Hipotesis nol dalam ANOVA satu arah adalah bahwa nilai rata-rata dari semua sampel adalah sama. Jadi jika ANOVA satu arah memberikan hasil yang signifikan, hanya dapat disimpulkan bahwa kedua data tidak sama.
Namun, seringkali peneliti tidak hanya tertarik pada hipotesis gabungan jika semua sampel adalah sama, tetapi juga ingin mengetahui pasangan sampel mana yang menolak hipotesis dengan nilai yang sama. Dalam hal ini dilakukan beberapa pengujian sekaligus, satu pengujian untuk setiap pasang sampel.
Beberapa uji perbandingan harus mengimbangi risiko mendapatkan hasil yang signifikan, meskipun hipotesis nol benar. Pendekatan ini bisa digunakan untuk mengoreksi nilai-p dalam memperhitungkan. Beberapa opsi untuk melakukan pendekatan ini adalah:
- Tukey HSD
- Holm-Bonferroni
- Tes Kruskal-Wallis
Tes Tukey
Tes Tukey, terkadang juga disebut sebagai metode Tukey Honest Significant Difference (HSD), mengontrol tingkat kesalahan Tipe I di beberapa perbandingan dan umumnya dianggap sebagai teknik yang dapat diterima. Ini didasarkan pada rumus yang sangat mirip dengan uji-t. Faktanya, uji Tukey pada dasarnya adalah uji-t, kecuali untuk mengoreksi beberapa perbandingan.
Rumus tes Tukey adalah:
dimana YA adalah yang lebih besar dari dua mean yang dibandingkan, YB adalah yang lebih kecil dari dua mean yang dibandingkan, dan SE adalah kesalahan standar dari data yang dimaksud. Nilai qs ini kemudian dapat dibandingkan dengan nilai q dari distribusi rentang pelajar, yang memperhitungkan beberapa perbandingan. Jika nilai qs lebih besar dari nilai kritis yang diperoleh dari distribusi, maka kedua mean tersebut berbeda secara signifikan. Perhatikan bahwa statistik jarak pelajar sama dengan statistik-t kecuali untuk faktor skala (np.sqrt (2)).
Metode Holm-Bonferroni
See: https://en.wikipedia.org/wiki/Holm%E2%80%93Bonferroni_method
Koreksi Bonferroni
Studentized range test (HSD) Tukey adalah tes khusus untuk perbandingan semua pasang k sampel independen. Sebagai gantinya kita dapat menjalankan uji-t pada semua pasangan, menghitung nilai-p dan menerapkan salah satu koreksi nilai-p untuk beberapa masalah pengujian. Pendekatan paling sederhana - dan pada saat yang sama cukup konservatif - adalah membagi nilai p yang diperlukan dengan jumlah pengujian yang kami lakukan (koreksi Bonferroni). Misalnya, jika Anda melakukan 4 perbandingan, Anda memeriksa signifikansi bukan pada p = 0,05, tetapi pada p = 0,0125.
Sementara beberapa pengujian belum disertakan dalam Python secara standar, Anda bisa mendapatkan sejumlah koreksi pengujian ganda yang dilakukan dengan paket statsmodels:
Koreksi Holm
Penyesuaian Holm secara berurutan membandingkan nilai p terendah dengan tingkat kesalahan Tipe I yang dikurangi untuk setiap pengujian berturut-turut. Misalnya, jika Anda memiliki tiga kelompok (dan dengan demikian tiga perbandingan), ini berarti bahwa nilai-p pertama diuji pada tingkat .05 / 3 (.017), yang kedua pada tingkat .05 / 2 (.025) , dan ketiga di tingkat .05 / 1 (.05). Metode ini umumnya dianggap lebih unggul daripada penyesuaian Bonferroni.
Metode Holm-Bonferroni adalah metode alternatif yang bisa digunakan.
Tes Kruskal-Wallis
Ketika kami membandingkan dua kelompok satu sama lain, kami menggunakan uji-t ketika data terdistribusi normal dan uji non-parametrik Mann-Whitney sebaliknya. Untuk tiga kelompok atau lebih, pengujian untuk data berdistribusi normal adalah uji ANOVA; untuk data yang tidak berdistribusi normal, uji yang sesuai adalah uji Kruskal-Wallis. Jika hipotesis nol benar, statistik uji untuk uji Kruskal-Wallis mengikuti distribusi kuadrat Chi.
Sampel acak dari tiga merek baterai yang berbeda diuji untuk melihat berapa lama pengisian daya berlangsung. Hasilnya adalah sebagai berikut:
Ujilah hipotesis bahwa fungsi distribusi untuk semua durasi merek adalah identik. Gunakan tingkat signifikansi 5%.
Hipotesis nol ditolak pada tingkat signifikansi 5% karena nilai-p yang dikembalikan kurang dari nilai kritis 5%.